RAG (Retrieval Augmented Generation) pipelines transform enterprise knowledge bases into powerful AI applications. These systems enable businesses to harness their existing data while maintaining complete control over sensitive information, making them a crucial component of modern LLM (Large Language Model) architectures.For the immediate pressure, ai knowledge base With its own coping style, it can break the predicament and usher in a new life through the quality of the product itself. https://www.puppyagent.com/
RAG pipeline LLM technology revolutionizes enterprise data interaction through intelligent retrieval and generation capabilities. Your organization gains the power to create context-aware AI applications that deliver accurate, relevant responses based on your proprietary knowledge, effectively reducing hallucinations commonly associated with large language models.
This guide reveals essential RAG pipeline implementation strategies for your business. You’ll discover:
Critical benefits that drive business value
Practical deployment approaches that work
Solutions to common implementation challenges
Steps to maximize your RAG pipeline’s potential
What Business Value Do RAG Pipelines Deliver?
business process
Image Source: Pexels
RAG pipelines drive competitive advantage for modern enterprises. McKinsey reports 47% of organizations now customize or develop their own generative AI models.
RAG pipeline technology eliminates extensive model training and fine-tuning costs. This translates directly to:
Reduced operational expenses
Faster AI application deployment
Streamlined implementation processes
Strategic benefits emerge across four key areas:
Real-time Data Access: LLM-powered solutions stay current with latest information
Enhanced Privacy: Sensitive data remains secure on premises, addressing data privacy concerns
Reduced Hallucinations: Responses gain accuracy through factual grounding, as retrieval augmentation reduces hallucination in large language models
Improved Customer Experience: Support teams access comprehensive knowledge instantly, enhancing chatbots and question answering capabilities
RAG pipelines transform operations across departments:
Marketing teams gain real-time customer insights and trend analysis capabilities. Research teams leverage immediate customer feedback for product innovation. Supply chain operations benefit from integrated ERP data analysis and supplier communication monitoring.
Retail businesses use RAG-based recommendation systems to incorporate trending products and customer preferences, driving sales growth and loyalty. Financial institutions enhance chatbot capabilities with current market data and regulatory information for personalized investment guidance.
What Components Make RAG Pipelines Successful?
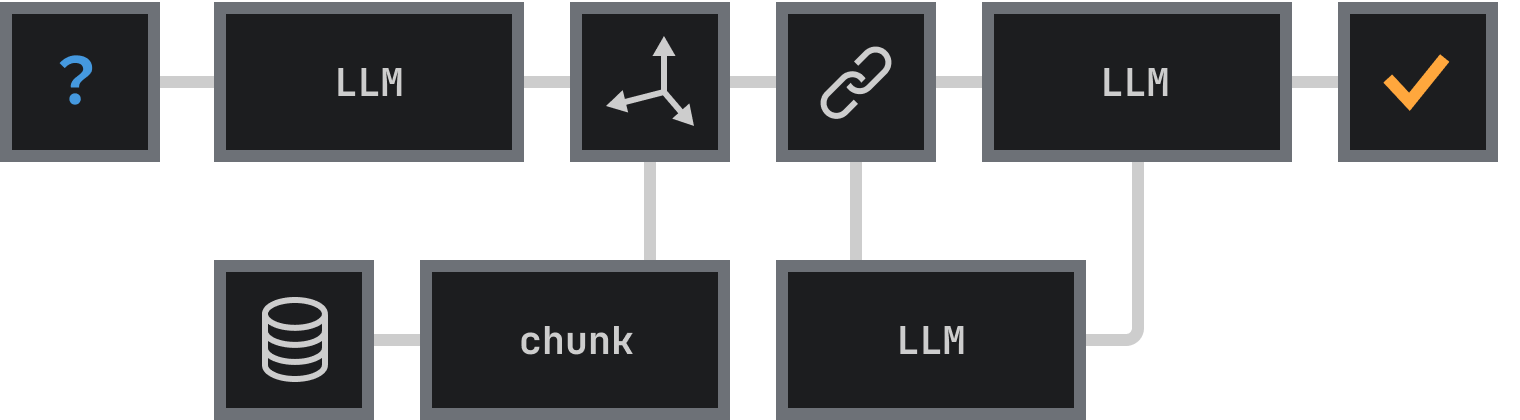
RAG pipeline success demands precise integration of critical elements. Your data pipeline forms the foundation, transforming unstructured information into efficient, usable formats. This process, known as the RAG process, involves several key steps and technologies.
RAG pipeline excellence requires these core components:
Data Processing Excellence: RAG systems demand thorough data cleaning protocols for maximum integrity
Strategic Content Chunking: Your content needs semantic division while preserving contextual meaning through text splitting techniques
Powerful Embedding Models: Text chunks transform into semantic vector representations using technologies like OpenAI Embeddings
Vector Database Optimization: Your embedded data needs efficient storage and indexing systems, such as the Chroma Vector Database
Automated Maintenance: Knowledge bases require consistet, automated updates
Data preprocessing quality determines RAG pipeline performance levels. Your raw data processing must:
Remove irrelevant content
Deploy error detection systems
Resolve issues rapidly
Content chunking strategies balance semantic preservation with size management. Your chunks must fit embedding model token limits while maintaining meaning
Vector database success demands sophisticated indexing mechanisms. These systems enable:
Fast result ranking
Efficient embedding comparisons
High retrieval accuracy
To enhance your RAG architecture, consider integrating tools like PuppyAgent. These frameworks provide powerful abstractions for building robust retrieval augmented generation pipelines, simplifying the process of connecting your LLM with external data sources.
What Implementation Strategies Drive RAG Pipeline Success?
RAG pipeline implementation demands strategic focus on security, scalability, and system monitoring. Your deployment strategy must prioritize data quality alongside operational reliability, considering the entire generation pipeline from data ingestion to final output.
Strategic implementation requires these core elements:
Security Protocol Design: RAG systems need encryption systems and secure key management
Performance Monitoring: System metrics require constant tracking for optimal operation, potentially utilizing tools
Quality Control Systems: Content filtering removes threats from data streams
Architecture Scalability: Parallel pipelines handle large-scale data processing
Testing Frameworks: Golden datasets enable continuous performance validation
RAG pipeline monitoring demands comprehensive logging systems. Your implementation must track:
Critical system events
User interactions
Performance metrics
External content protection requires sophisticated filtering mechanisms. Your system should:
Detect malicious content
Remove misleading information
Route sub-85% confidence cases to human review
Performance optimization demands specialized chunking strategies. Your system needs:
Document corpus size
Real-time data requirements
System performance needs
To further enhance your RAG pipeline, consider implementing advanced techniques such as:
Similarity searches using cosine distance metrics for more accurate retrieval
Query reformulation to improve the quality of LLM-generated responses
Re-ranking of retrieved documents to prioritize the most relevant information
These strategies can significantly improve the performance and accuracy of your retrieval augmented generation system.
Why Choose RAG Pipelines for Your Enterprise?
RAG pipelines revolutionize enterprise knowledge management through AI technology integration. Your business gains:
Enhanced data security protocols
Reduced operational expenses
Precise AI response systems
Complete control over sensitive information
Success demands attention to fundamental components:
Data processing excellence
Vector database optimization
Security protocol implementation
Performance monitoring systems
RAG pipeline deployment transforms enterprise operations through:
Focused use case implementation
Systematic capability expansion
Performance-driven scaling
Data-powered decision making
Start small. Focus on specific business challenges. Let performance metrics guide your expansion. RAG pipelines reshape enterprise knowledge management, turning information assets into powerful decision-making tools.
By leveraging the power of large language models in combination with your proprietary data, RAG pipelines offer a compelling solution for businesses looking to enhance their AI capabilities while maintaining data privacy and reducing computational costs.